Introduction
Machine Learning
Avant de chercher à comprendre ce que c'est que le reinforcement learning, il faut savoir que c'est un sous domaine du machine learning. Mais qu'est-ce que le machine learning ?
Machine learning ou apprentissage automatique, est une branche de l'intelligence artificielle étudiant les algorithmes permettant à une machine d'évoluer ou "apprendre" progressivement à l'aide de données et ainsi répondre à des problèmes impossibles à résoudre par les régles classiques de programmation (if . . . then).
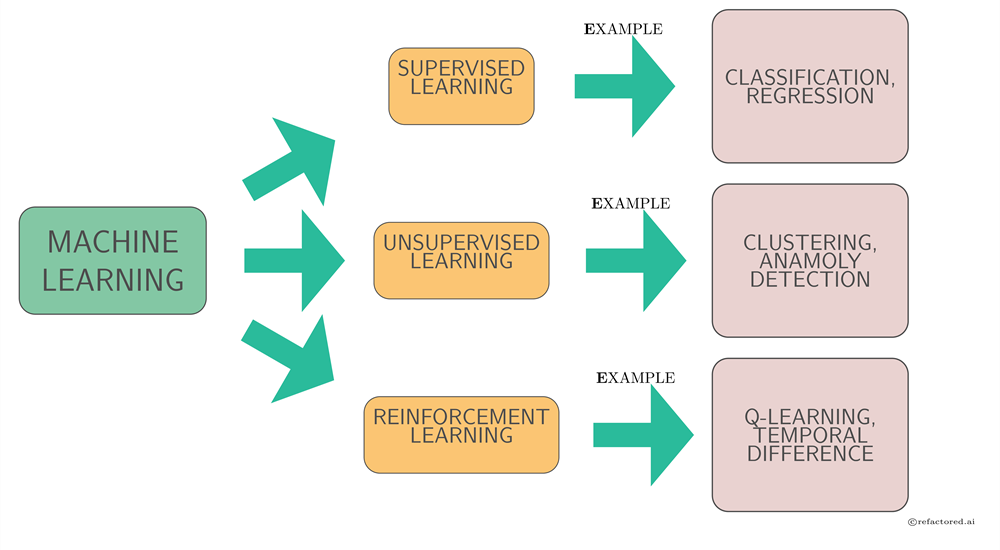
Les 3 types d'apprentissage avec des exemples
Supervised, unsupervised, reinforcement learning
En machine learning, on distingue principalement 3 paradigmes d'apprentissage et qui sont imposés par le type de tâches qu'on cherche à effectuer ainsi que les données à disposition. Ces types d'apprentissage sont :
Supervised learning
Unsupervised learning
Reinforcement learning
Supervised learning ou apprentissage supervisé est la technique d'apprentissage visant à automatiquement des règles à partir d'une base de données d'apprentissage contenant des « exemples » (en général des cas déjà traités et validés). Les exemples (ou échantillons d'entraînement) sont des paires entrées-sorties.
Un exemple simple de l'apprentissage supervisé est la classification supervisée : étant donné un nombre fini d'étiquettes bien connues, le but de la classification est d'associer à chaque échantillon une étiquette. L'apprentissage supervisé veut dire qu'on dispose d'exemples dont l'étiquette est connue et qui serviront à entraîner le modèle.
L'apprentissage non supervisé est le problème d'apprentissage où le programme doit trouver des structures sous-jacentes à partir de données non étiquetées
Le clustering (ou segmentation) est l'exemple le plus connu de l'apprentissage non supervisé. Il consiste à regrouper entre eux les échantillons ayant des propriétés semblables et pouvant appartenir à une même structure. Google News utilise ce système afin de regrouper les news traitant du même sujet de manière automatique.
L'apprentissage par renforcement fait référence à une classe de problèmes d'apprentissage dont le but est d'apprendre, à partir d'expériences, ce qu'il convient de faire en différentes situations, de façon à optimiser une récompense quantitative au cours du temps.
Un paradigme classique pour présenter les problèmes d'apprentissage par renforcement consiste à considérer un agent autonome, plongé au sein d'un environnement, et qui doit prendre des décisions en fonction de son état courant. En retour, l'environnement procure à l'agent une récompense, qui peut être positive ou négative. L'agent cherche, au travers d'expériences itérées, un comportement décisionnel (appelé stratégie ou politique, et qui est une fonction associant à l'état courant l'action à exécuter) optimal, en ce sens qu'il maximise la somme des récompenses au cours du temps.
Un peu d'histoire !
Parmi les premiers algorithmes d'apprentissage par renforcement, on compte le Temporal difference learning (en) (TD-learning), proposé par Richard Sutton en 1988, et le Q-learning mis au point essentiellement lors d'une thèse soutenue par Chris Watkins en 1989 et publié réellement en 1992.
Toutefois, l'origine de l'apprentissage par renforcement est plus ancienne. Elle dérive de formalisations théoriques de méthodes de contrôle optimal, visant à mettre au point un contrôleur permettant de minimiser au cours du temps une mesure donnée du comportement d'un système dynamique. La version discrète et stochastique de ce problème est appelée un processus de décision markovien et fut introduite par Bellman en 1957.
D'autre part, la formalisation des problèmes d'apprentissage par renforcement s'est aussi beaucoup inspirée de théories de psychologie animale, comme celles analysant comment un animal peut apprendre par essais-erreurs à s'adapter à son environnement. Ces théories ont beaucoup inspiré le champ scientifique de l'intelligence artificielle et ont beaucoup contribué à l'émergence d'algorithmes d'apprentissage par renforcement au début des années 1980.